使用Python是个很有意思的体验,语法相对简单,各种包的支持也非常到位,因此无论用Python解决什么问题,都觉得弹指间可以让其灰飞烟灭。作为一个工具,一种编程语言,在帮助不同人群实现各种有趣的小目标这点上,Python真的是无出其右。
本文目的
Python中有一种很好玩的应用,就是爬虫,简单说就是通过它,用户可以抓取网页上的信息。比如,在本篇文章中,我就将介绍自己爬取Pythonbooks网站的过程,以此来让各位对爬虫有个大概的认识,并且描述过程中我也会顺带介绍一下Selenium和BeautifulSoup两个爬虫中常用包的用法。
在Python的学习过程中,我相信每一位“Pythoner”都会经历这样一个过程:市面上这么多本Python的书籍和教程,究竟哪一个才是最好的呢?国外有个叫Dibya Chakravorty的哥们在当初学习Python的时候也思考到这个问题,于是他就做了一个网站,Pythonbooks.org,专门来统计不同应用领域下的Python书籍,以及它们的评分,评分是根据书的销售情况来计算的。所以今天我就用爬虫的方式来带各位看一下他网站上是怎么说的。
环境需求
我是在Python3下运行的爬虫,用到的包就两个:Selenium和BeautifulSoup,安装最新版就可以。
下面我们先来看一下这两个包究竟都是做什么的,为什么我会用到它们。
Selenium和BeautifulSoup
打开Selenium官网,第一句话就是 Selenium automates browsers. 。没了,就这一句,就说明了Selenium的作用,它就是用来模拟操作浏览器的工具,通过API,用户可以用代码来操作浏览器上网页的跳转,关闭,填写表单等操作。
那BeautifulSoup的作用呢?以下引用Wikipedia:
Beautiful Soup is a Python package for parsing HTML and XML documents (including having malformed markup, i.e. non-closed tags, so named after tag soup). It creates a parse tree for parsed pages that can be used to extract data from HTML, which is useful for web scraping.
所以BeautifulSoup的作用就是用来从HTML和XML等文件中提取所需信息。BeautifulSoup实际上是bs4模块的一个子模块,bs4的作用极其强大,可以针对各种内容分割和获取信息,BeautifulSoup是其专门针对HTML和XML的。因为本文只用到BeautifulSoup,因此其他的模块内容就暂不介绍了,有兴趣的朋友可以自行查阅。
简单介绍两个工具包之后,接下来让我们开始网站的爬取工作吧。
网站爬取
在正式爬取之前,我们还有一个问题需要解决,就是这个网站的规模和动态程度,如果只是纯静态网页,而且只要爬取一个页面,那其实很容易。或者如果只要爬取3、5个网页,那我们完全可以手动跳转每个网页然后运行一遍程序,也不过就运行3、5遍而已,但当网页数量比较多的时候,这么不自动化的办法就显得很麻烦。
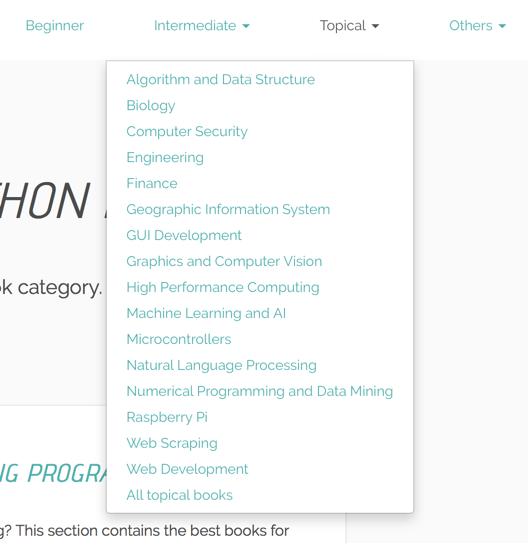
这个网站上已经针对不同领域,为用户区分好了所有的Python书籍归属种类。这点真的非常方便,这样我就只需要按照他网站给出的分类分别爬取下来就可以了,但这里种类的繁多,一个网页一个网页的手动跳转就很麻烦了,所以这里就需要Selenium来模拟鼠标的点击操作,进行网页的跳转,然后用BS爬取内容。这就是整个爬取过程的初步思考。
初始化webdriver
1 | def init_driver(): |
用Selenium来模拟浏览器的各种行为,就需要先进行webdriver的初始化,如上面的代码所示。中间注释掉的那一行可加可不加,它的作用主要就是考虑到有些网页是动态呈现内容,在输入网址之后加载网页到完全加载完毕可能需要等待一段时间,WebDriverWait就是用来告诉driver可以考虑的等待时间范围。一般来说都会搭配该类下的unitil、until_not方法和expected_conditions使用,本文用不到这些内容,所以就不深讲了,有兴趣的朋友可以看这里
爬取分类
从这里开始,我们就要正式爬取网站内容了。首先需要先把所有的分类获取,这样也方便我们最后整理信息,无论是以哪种方式存储。
1 | url = "http://pythonbooks.org/" |
这里有细心的朋友可能看到我一开始给了一个categories的字典变量,里面有内容,而不是空的。这里之所以这样做,是因为在网页上显示的四个总分类中,只有Beginner是没有下级菜单的,所以这里就单独处理一下。
代码中driver.find_element_by_xpath("//li[@class='dropdown open']"),这句就是获得了弹出的下级菜单中的内容。具体的对照请看下图:
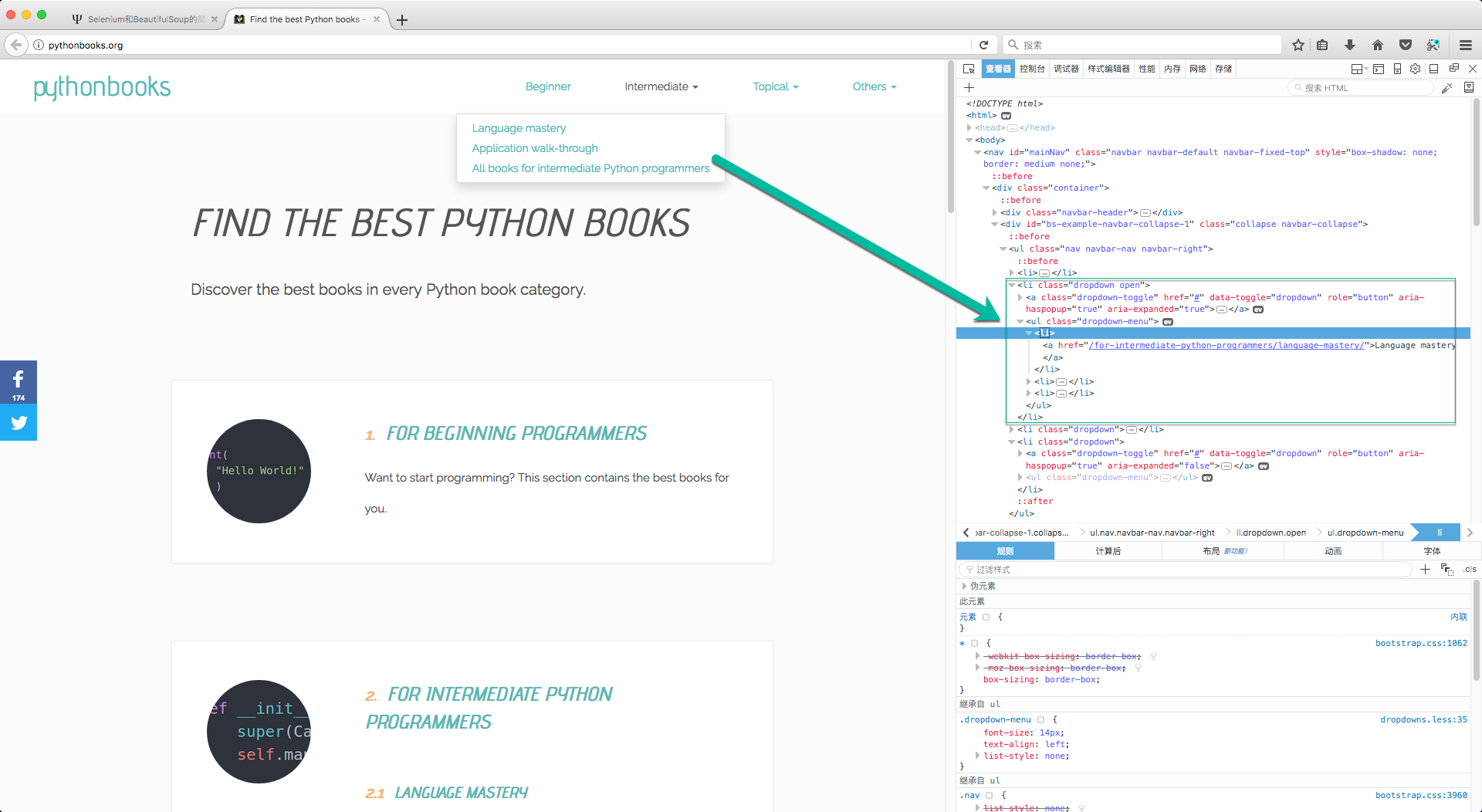
for循环中,两个遍历的变量,前者是获取的分类的string值,后者是对应的链接地址。我将它们都存进一个字典中,这样在下面爬取内容的时候,只需要对该字典遍历一遍就可以了。
爬取书籍信息
上面我们已经将书籍分类都汇总好了,下面就开始挨个网页的爬取书籍的信息。这里书籍的信息我主要就爬取了五个:标题,作者,出版日期,分数,和封面图像。为了存储和打印方便,我就讲书籍信息封装成一个类,如下所示:
1 | class BookInfo(): |
接下来就是对页面的爬取工作,先贴代码:
1 | def crawl_book_info(driver, url): |
内容比较多,我们一点点来看。首先我们看看每个字段的位置。
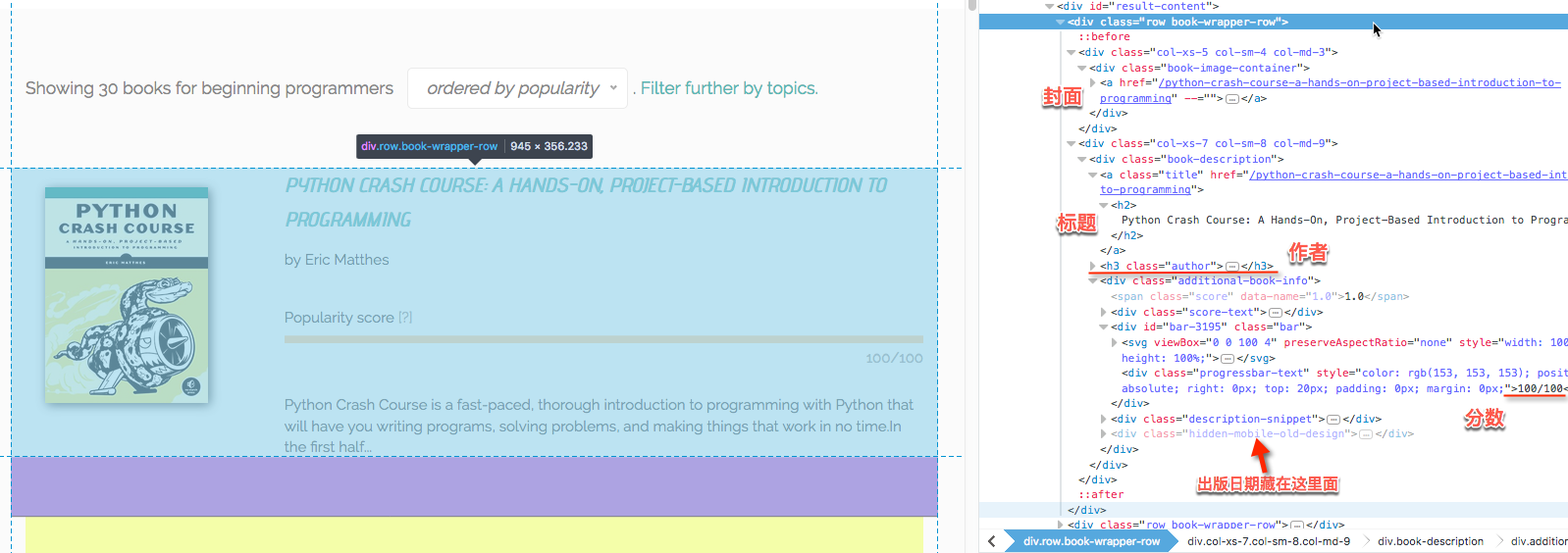
我在一开始做这部分的时候是想用BS就可以了,因为在HTML中各元素的位置一目了然,爬取十分方便。但后来发现分数这一项,死活爬不下来,每次用BS去找这一块,返回的都是空。猜测可能是分数是动态生成的关系,因此BS抓取不到,具体内在原因没有去详细了解,如果有大神知道是怎么回事,还希望不吝赐教。后来我实在没有办法,就只好改用Selenium来抓取,driver.find_elements_by_xpath("//div[@class='bar']")。正因为分数是动态生成,所以在加载网页之后需要给一个延迟,等一下分数的刷新。分数和书籍是一一对应的,所以在for循环中用zip对两者一起进行协同遍历就可以了。
存储书籍信息
我们已经将书籍信息全部抓取下来,下面就是要考虑如何存储的问题。我这里是将所有的书按照分类(如果有第二级分类,就按照第二级)存储到一个markdown文件里。markdown最大的有点是,很方便转成html文件,这样既利于存储也利于展示。代码如下,因为这部分比较简单,我想就不用解释太多了。
1 | def book_save(books_list, cat, sub_cat=None): |
主函数:功能串联
主函数主要就是将各个部分串联起来,具体代码如下:
1 | if __name__ == "__main__": |
在所有的分类中,只有Beginner是没有二级分类的,因此需要对它进行单独处理。对应到代码中,就是except下面的内容。
我在主函数里还设置了一个all_books的变量,但其实并没有用到。因为一开始我本打算先存到一个字典变量中在,再对该变量进行遍历,一个一个将书籍信息存到文件中。后来发现其实并不需要,完全可以边爬取边存。
好了,所有的爬取内容就都结束了,当你运行程序之后就会看到Firfox浏览器自动弹出,然后逐个页面的自己跳转,最后浏览器关闭的时候,你也就收获了一大堆的md文件。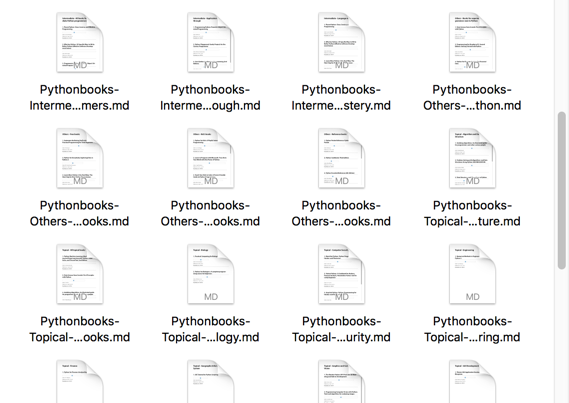
md的内容如下图所示: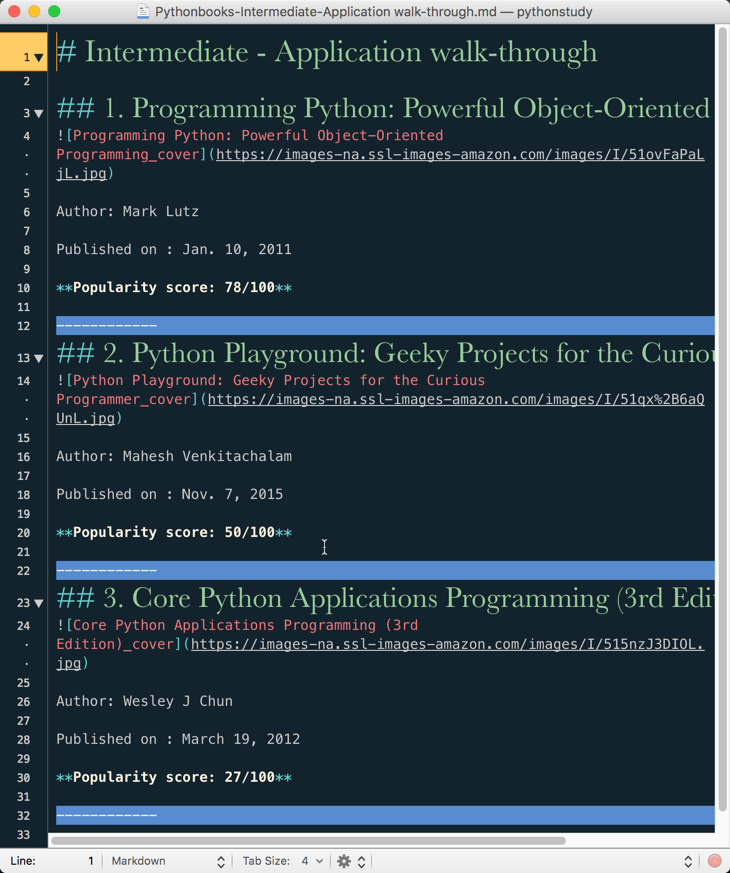
将md渲染成HTML后在网页中显示是这样的:
结语
相对来说,这次的爬取任务很简单,因为网站没有反爬机制。其实在爬取过程中,最难的,最体现斗智斗勇的地方,就是反爬与反反爬,这方面我不是很了解。因为一般用到爬虫的时候都是确实切身需要的时候,并非为了技术而去钻研,所以大部分时候爬的都是一些明面上的可搜集的数据。网上关于Python爬虫的介绍和例子其实有很多很多,现如今,除了数据分析,机器学习这部分,恐怕大多数人都是因为爬虫的趣味性和实用性在学Python吧。
在本文的最后,我给出了几个很有帮助的链接,对于想要学习Selenium和BeautifulSoup的朋友,值得一看。