记得很早的时候,刚开始接触搜索引擎,那时候Google还没有被墙,百度也是刚刚诞生没多久,无论我在输入框内输入什么,只是显示我输入的内容,并没有任何联想功能提示我接下来可能匹配的内容。有时候想找个东西,可就是死活想不起来准确的名字或者描述方式,这个时候搜索引擎也帮不了你,你只能变着法的尝试各种输入,来寻求最终你想要的结果。后来搜索引擎加入了联想功能,这着实是一大进步,极大地提高了搜索效率。有的时候,我们对于想查询的某一问题的提问方式是很模糊的,这个时候当你输入了一些关键词,发现搜索引擎会根据你的输入给你一些后续内容的建议,会让你更容易的找到自己想要的答案。
本文目的
上一篇我在《用Python在Hadoop上跑MapReduce》中介绍了一些关于如何利用Hadoop Streaming运行Python版MapReduce的简单操作,如何实现词频统计就像是MapReduce中的Hello World,不过做完了入门教程,为了深入学习,还得需要更多的练习。
在这篇文章中,我将会带各位实现一个很简单的搜索联想功能,比较粗糙,但是看起来也挺像那么回事的~
正文
为了实现autocomplete,首先需要搞清楚它背后的原理,搜索引擎究竟是根据什么来给出提示的?比如我输入一个autocomplete之后,为什么后面推荐的是python,algorithm之类的,而不是Naruto,One Piece这些呢?
无论是百度还是谷歌,其实在大家用它们的搜索引擎收集你需要的信息的时候,它们也同样在收集信息。它们收集了大量的用户搜索的输入信息,同时还在抓取各种网页内容的信息,简单来说,搜索引擎通过某种算法将各种收集到的资料综合到一起,最终给出了一个输入联想的列表,这就是自动补全功能。
私下里作为学习MapReduce的项目,我们肯定不可能去试图实现真正的搜索引擎。不过做一个简陋版的,帮助自己理解autocomplete背后的实现原理,以及如何利用MapReduce来实现,也是足够的。
N-Gram
对于autocomplete背后实现的原理,很重要的一点就是N-Gram,这篇文章有简明的介绍,举个例子好了:implement search autocomplete in python
- 这句话如果按2-Gram划分的话,就是
implement search,search autocomplete,autocomplete in,in python; - 那么按照3-Gram划分的话,就是
implement search autocomplete,search autocomplete in,autocomplete in python; - 按照4-Gram划分的话,就是
implement search autocomplete in,search autocomplete in python; - 按照5-Gram划分的话,就是一整句话,不作任何切割。
这里我没有给出1-Gram的例子,各位可以思考一下是为什么,这里先卖个关子,下面会提到原因。这里我们先回头思考一下搜索引擎给出的联想词汇,比如我输入了一个autocomplete,那么后面你觉得是给出in python看上去更自然还是Transformer更合理?显然是前者对么,如果给出了后者,你可能会想:autocomplete Transformer是什么鬼?!难道是某种新型变形金刚么?没听过啊!那之所以会有这样的感觉,是因为从我们平时获取的信息中,我们对于autocomplete这个词后面的衔接词接收到的也是in python远远多于Transformer,对吧?所以说到这里就大概有点明晰了,搜索引擎对于联想词汇的推荐也有这方面的考虑,我们给输入一个或多个引导词,autocomplete功能将后面最有可能出现的几种选择展现给我们。所以这也是为什么用到N-Gram的原因,这里其实就是一个句子分割的过程。
那么这里就引出了下一个问题:是该基于一句话最后一个词来预测后面的推荐,还是根据更多的词甚至一整句来预测下面的出现呢?
还继续以上面的例子说好了。假设我已经输入了implement search autocomplete in,如果是按照最后一个出现的词来进行联想,那么in后面其实可以跟很多很多内容,都不会违和,对吧?比如in box,in air,in heart等等,但如果把这些联想放到一整句中,显然是不太合理的。因此,我们在实现autocomplete的时候,其实是基于N-Gram预测N-Gram。
那到这里,其实autocomplete的实现的大致思路就应该有了。我们需要将大批量的文档用N-Gram的处理方式进行切割,统计相同短语出现的频次,构建N-Gram的模型,然后找出每个短语之后出现频次最高的几个词汇作为预测保存下来。最终将结果存入数据库,以方便之后调用。下面我们就来看看如何一步步具体实现。
MapReduce实现
N-Gram模型构建
在这次的代码实现中,我们需要用到两个mapper和reducer。首先,我们需要一对mapper和reducer将输入的文档进行切割。
n_gram_mapper.py
1 | import sys |
如果你想构建一个N=5的N-Gram模型,那么在mapper里,就需要将2到5的分割方式都输出。还记得上面我有留一个悬念,为什么不考虑1-Gram么?因为显然1-Gram是没有用的,它并不能告诉我一个短语后面可能出现的词有什么。
n_gram_reducer.py
1 | import sys |
这回的reducer我用到了generator来调用数据,这样做可以有效节省内存占用空间。因为随着输入数据量的越来越大,即便是5-Gram,依然也是个很庞大的记录数量。下面的主函数部分,我也放弃了之前的简单用法,用groupby可以明显提升代码的阅读逻辑,对itertools.groupby不太熟悉的朋友可以看这份官方文档。
N-Gram测试结果
做下一步之前,我们先来本地测试一下这一对mapper和reducer是否好用。
测试文档:我直接把MapReduce的Wiki里头一段关于它的说明解释,粘贴下来作为测试文档用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23root@hadoop:~/src/p2py# cat input/file2.txt | ./n_gram_mapper.py | sort | ./n_gram_reducer.py
a cluster 1
a good 1
a good mapreduce 1
a good mapreduce algorithm 1
a map 1
a map procedure 1
a map procedure method 1
a map procedure method that 1
a mapreduce 1
a mapreduce program 1
a mapreduce program is 1
a mapreduce program is composed 1
...
and reduce 3
and reduce capabilities 1
and reduce functions 2
...
map and 3
map and reduce 3
map and reduce capabilities 1
map and reduce functions 2
...
我这里就截取一部分结果,实在太长了……
构建预测概率的模型
我们现在已经有了N-Gram切割后的结果了,下一步就是要在此基础上分析每一个词汇或者短语后面可能出现的内容,这里其实可以理解成构建一个概率模型,很简单一个概率模型。
举例说明,我们先来看刚才的结果生成的一部分1
2
3
4
5
6
7
8
9and data 1
and development 1
and fault 3
and generating 1
and less 1
and providing 1
and reduce 3
and scatter 1
and sorting 1
先仅仅分析and之后可能出现的词汇,所有的情况都在这里摆着了。那这时候autocomplete会如何给出推荐呢?很显然的,fault和reduce会放到头两个推荐对吧,为什么?这其实就是个概率的问题:and后接一个词在文中出现了1+1+3+1+1+1+3+1+1=13次,那fault和reduce推荐的概率就是3/13,剩下的所有都是1/13的概率。对于autocomplete系统来说,这意味着当用户输入了and之后,它认为用户更有可能继续输入的是fault和reduce,因为从它以往经验(系统所得到的输入)来看,fault和reduce出现的频次更多一些,相比较于其他的结果。因此,下一步工作,我们需要得到一个类似于and<\t>data=1这样的数据记录样式,来统计所有的短语之后跟随的词汇以及它出现的频次。这里我们之所以不用概率来进行记录,是因为从刚才的计算过程来看,词频和概率是正相关的,那么就没必要多算一步记录概率了。
prob_mapper.py
1 | import sys |
mapper的工作其实很简单,基本没有什么需要说明的。需要注意的是,这里我加入了一个threshold参数,意义是为了筛选掉一部分出现频次太低的结果。刚才举的例子里,每个结果出现的频次其实都不高,这样threshold肯定是没用的,但实际生产中,比如像Google和百度这样的超大规模的搜索引擎,每天可能抓取的数据量十分庞大。事实上,我们每次在搜索框中输入内容,得到的联想其实都在二十条以内,一般来说不会给太多的,太多的话,用户筛选起来也是个麻烦。那对于那些基本很少出现的词组组合,也就没必要存储下来,被搜索到的概率太低,如果全部都记录下来,对数据库的存储容量是个很大的负担。
prob_reducer.py
1 | import sys |
starting_phrase代表的是用户输入的部分,following_word代表的是后面可能出现的词汇,count顾名思义就是指词频了。在reducer中,我们先按照词频的不同将可能出现的词汇分组放置,然后再根据我们需要的N-Gram大小来依次输出。这里的参数n_gram和之前n_gram_mapper里的n_gram意思一样,但取值可以不同。
预测概率的测试结果
下面我们来看看本地测试结果吧,就用上一步n_gram_reducer得出的结果继续操作。
1 | root@hadoop:~/src/p2py# cat result.txt | ./prob_mapper.py | ./prob_reducer.py |
因为之前在mapper里我们将threshold设置为2,这里我们就可以看到结果中只有词频不小于2次的。
运行在Hadoop上
刚才在本地跑过了之后,下面来进行Hadoop上的测试。为了方便快捷,我编写了一个script来运行两对mapper和reducer,最后把得到的数据从HDFS里导出到本地。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27root@hadoop:~/src/p2py# ./run_script.sh
Cleaning old results in /output...
17/10/10 01:30:20 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /output
Running python in Hadoop by hadoop streaming...
packageJobJar: [/tmp/hadoop-unjar5398292596529368576/] [] /tmp/streamjob5913697815224381390.jar tmpDir=null
17/10/10 01:30:22 INFO client.RMProxy: Connecting to ResourceManager at hadoop-master/172.18.0.2:8032
17/10/10 01:30:22 INFO client.RMProxy: Connecting to ResourceManager at hadoop-master/172.18.0.2:8032
17/10/10 01:30:23 INFO mapred.FileInputFormat: Total input paths to process : 1
...
17/10/10 01:30:49 INFO streaming.StreamJob: Output directory: /output/first
Running 2nd mapper and reducer...
packageJobJar: [/tmp/hadoop-unjar6814698868258273333/] [] /tmp/streamjob6470458846508985375.jar tmpDir=null
17/10/10 01:30:51 INFO client.RMProxy: Connecting to ResourceManager at hadoop-master/172.18.0.2:8032
17/10/10 01:30:51 INFO client.RMProxy: Connecting to ResourceManager at hadoop-master/172.18.0.2:8032
17/10/10 01:30:52 INFO mapred.FileInputFormat: Total input paths to process : 1
...
17/10/10 01:31:13 INFO streaming.StreamJob: Output directory: /output/second
Moving outputs from HDFS to local...
Got the output!
一切顺利运行!最终结果也被成功导出到本地。
导入数据库
其实到上一小节,MapReduce的工作就都做完了,但为了让autocomplete可以展现出应有的效果,这里还需要将刚才生成的数据导出到数据库中,以便之后和Web结合来体现功能。
数据库我用的是MySQL,大家可以任意选择。下面是我的数据库操作代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import sys
import MySQLdb as mdb
def read_data(file):
for line in file.readlines():
yield line.strip().split(",")
def main(input_data):
with mdb.connect('localhost', 'username', 'password', 'dbname') as cur:
cur.execute("DROP TABLE IF EXISTS output")
cur.execute(
"CREATE TABLE output(starting_phrase VARCHAR(250), following_word VARCHAR(250), count INT)")
with open(input_data, 'r') as file:
for starting_phrase, following_word, count in read_data(file):
cur.execute(
"INSERT INTO output(starting_phrase, following_word, count) \
VALUES('{}', '{}', {})".format(starting_phrase, following_word, count))
if __name__ == '__main__':
main("output")
数据库中显示的结果: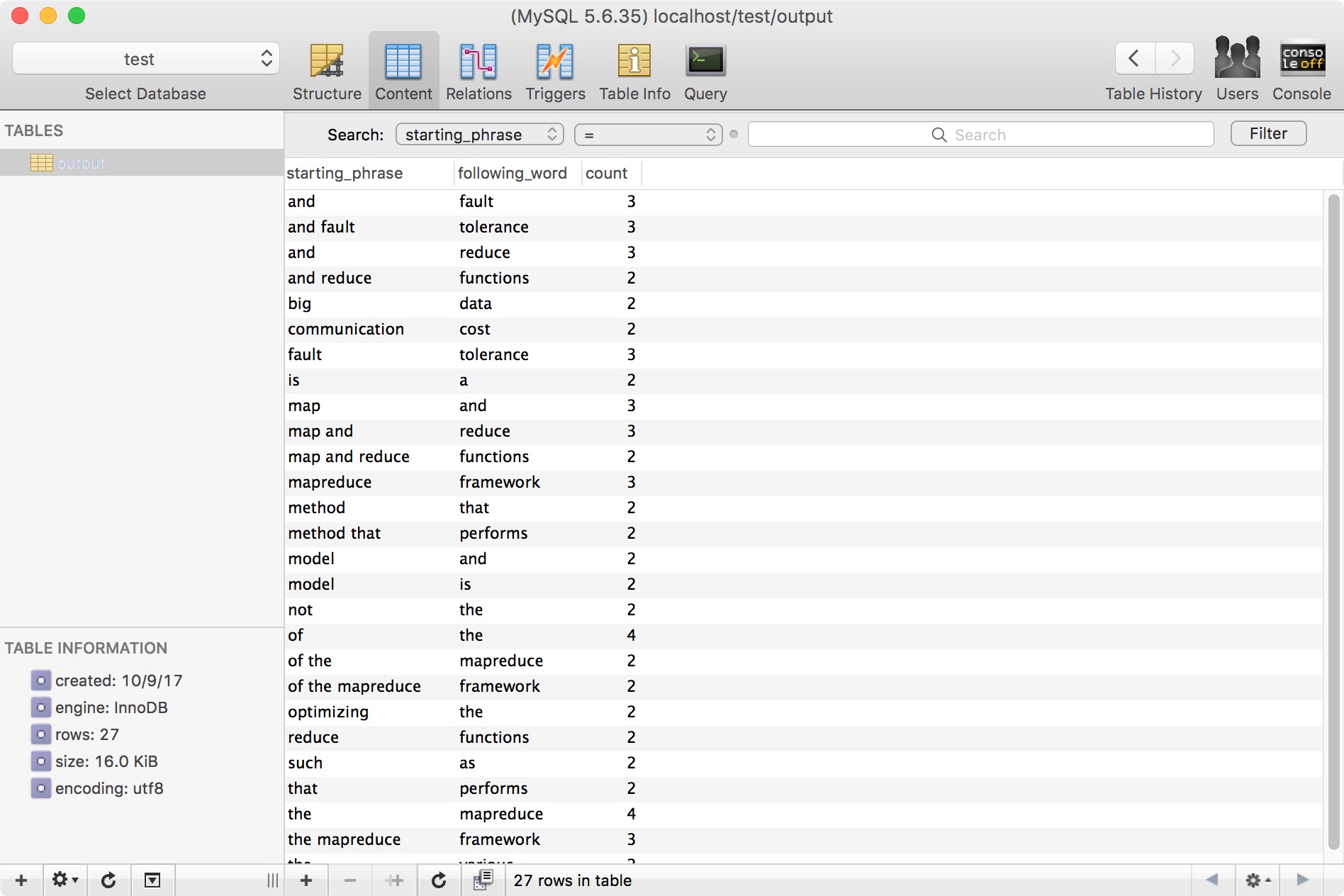
展示结果
我简单做了一个Web展示的页面,基于Ajax和PHP,连接数据库后,测试结果如下图所示: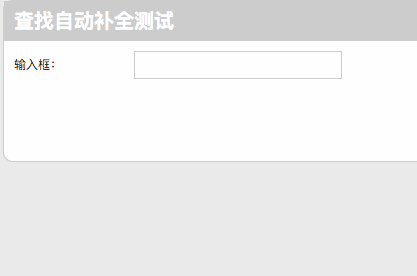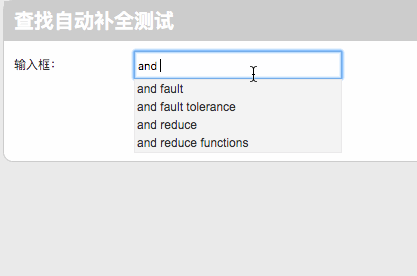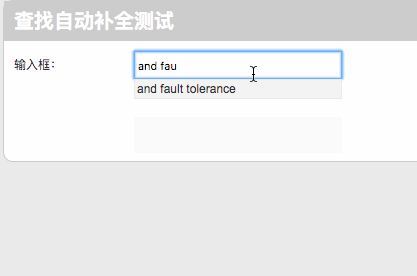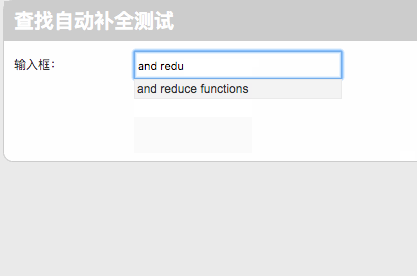
总结
本文从零开始,不太详细的介绍了autocomplete的工作原理,以及如何利用Python和MapReduce来处理数据。相比较Java实现这些内容而言,Python确实需要注意更多的细节,毕竟Java是Hadoop原生环境,configuration的配置真的是方便。之前做wordcount时没有觉得Python+Hadoop Streaming的方式有什么问题,因为Python天生的简洁特质,感觉比Java啰里啰嗦的舒服多了。但这次的代码实现上就看出端倪了,Python下更多的细节部分需要开发者自己写代码去维护,就像不同的mapper,reducer之间的数据传输,还有输出到数据库保存。
一路从头看到这里的朋友,感谢你的阅读,如果有疑惑,欢迎👇下面留言,如果文章中有什么不对的地方,也欢迎批评和指正。